Water Quality Simple Steps For Mitigating Cybersecurity Risk Discover the simple steps that water utilities can take to easily, affordably, and sustainably improve their cybersecurity
Water Quality Hach WIMS Frequent Questions: Hach WIMS Frequently asked questions answered by Aquatic Informatics Technical Sales Engineer Tyrone Yan.
Wastewater Hach WIMS Frequent Questions: Hach WIMS Frequently asked questions answered by Aquatic Informatics Product Manager Kevin Koshko.
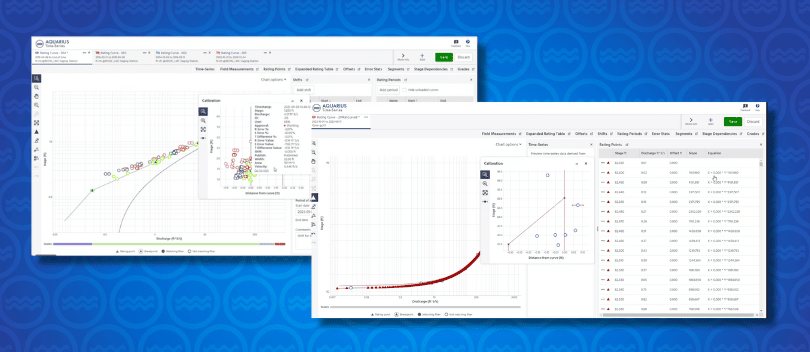
Hydrology Introducing the Rating Review Tool: Introducing the Rating Review Tool: a new step forward for raving curve reviews replacing RDT.
Water Quality WIMS Rio Frequent Questions: WIMS Rio Frequently asked questions answered by Aquatic Informatics Technical Sales Engineer Tyrone Yan.
Hydrology How to Monitor and Manage Groundwater Get the full interview between Nicole Nally and H2O Global discussing how Aquarius can help solve groundwater monitoring challenges.
Hydrology Best Practice Approach to Stage-Discharge Rating Curve Development Discover best practices to developing stage-discharge rating curves.
Wastewater 5 Ways Rio Software Has Improved Penn Yan Facility’s Operations Learn about the 5 Ways Rio has Improved Penn Yan Facility's Operations & Compliance.
Water Quality 7 Ways to Quality Control Environmental Data Learn about the 7 New Ways to Quality Control Environmental Data Such as Wind & Water in Real-Time
Wastewater Overcoming Utility Workforce Challenges with Software Learn more about how to overcome utility workforce challenges by leveraging modern compliance & operations software.
Hydrology Predictive Analytics in Water Monitoring Guest Blog: Program Manager Erin Lim explains the top benefits of leveraging predictive analytics in your water monitoring program
Business Aquatic Informatics Announced BC’s Top Employer for Third Year Click here to learn why Aquatic Informatics, a mission-driven software company, is one of BC's Top Employers for the third year.
Hydrology Centralizing Data to Protect the Chesapeake Bay Centralizing data, Scientists at Chesapeake Biological Laboratory use an online platform to manage, host and workup data.