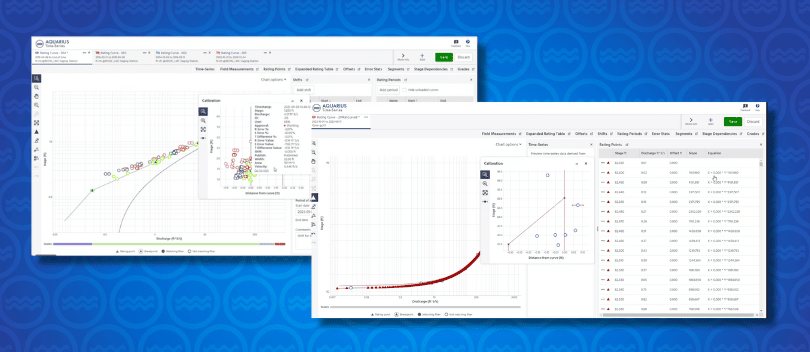
Introducing the Rating Review Tool: a new step forward for raving curve reviews replacing RDT.
Hydrology
How to Monitor and Manage Groundwater
Get the full interview between Nicole Nally and H2O Global discussing how Aquarius can help solve groundwater monitoring challenges.
Hydrology
Aquarius HydroCorrect FAQ: Answered by Aquarius Product Manager
Read our full blog for answers to Frequently Asked Questions about Aquarius HydroCorrect, answered by Aquarius Product Manager Symone Kumar.
Hydrology
Best Practice Approach to Stage-Discharge Rating Curve Development
Discover best practices to developing stage-discharge rating curves.
Hydrology
Predictive Analytics in Water Monitoring
Guest Blog: Program Manager Erin Lim explains the top benefits of leveraging predictive analytics in your water monitoring program
Hydrology
Centralizing Data to Protect the Chesapeake Bay
Centralizing data, Scientists at Chesapeake Biological Laboratory use an online platform to manage, host and workup data.
Water Quality
Simple Steps For Mitigating Cybersecurity Risk
Discover the simple steps that water utilities can take to easily, affordably, and sustainably improve their cybersecurity
Hydrology
The Quest for Alpha
Learn about the importance of the value of alpha, how it varies for your own sites, and how predictable it is.
Hydrology
When Experience Matters: Stream Gauging at the Limits of Technology
The North American Stream Hydrographers (NASH) hosted a Q competition at the Alberta Irrigation Technology Center (AITC) in Lethbridge, Alberta on June 8th. However, this...
Hydrology
How Good Is Good Enough?
The New Zealand Hydrological Society hosted an ADCP flow regatta as part of the Technical Workshop in Dunedin from April 3-6. The field event followed...
Hydrology
Hydrometry & Hydrology – The Next Generation
At Aquatic Informatics, we are encouraged to take an active role in the community and so I was quick to agree when I was recently...
Hydrology
USGS Goes Live With AQUARIUS Time-Series Software
The United States Geological Survey (USGS) has replaced its custom, in-house developed, Automated Data Processing System (ADAPS) originally designed in 1985 with the commercial-off-the-shelf (COTS)...